An Image is Worth Multiple Words: Discovering Object Level Concepts using Multi-Concepts Prompts Learning
ICML 2024
Chen Jin1
Ryutaro Tanno2
Amrutha Saseendran1
Tom Diethe1
Philip Teare1
1 AstraZeneca 2 Google DeepMind
Paper
Code
Dataset
Video

TL;DR: We propose a framework that allows us to discover and manipulate multiple concepts in a given image with partial text instructions.
Abstract
Textural Inversion, a prompt learning method, learns a singular embedding for a new "word" to represent image style and appearance, allowing it to be integrated into natural language sentences to generate novel synthesised images. However, identifying and integrating multiple object-level concepts within one scene poses significant challenges even when embeddings for individual concepts are attainable. This is further confirmed by our empirical tests. To address this challenge, we introduce a framework for Multi-Concept Prompt Learning (MCPL), where multiple new "words" are simultaneously learned from a single sentence-image pair. To enhance the accuracy of word-concept correlation, we propose three regularization techniques: Attention Masking (AttnMask) to concentrate learning on relevant areas; Prompts Contrastive Loss (PromptCL) to separate the embeddings of different concepts; and Bind adjective (Bind adj.) to associate new "words" with known words. We evaluate via image generation, editing, and attention visualization with diverse images. Extensive quantitative comparisons demonstrate that our method can learn more semantically disentangled concepts with enhanced word-concept correlation. Additionally, we introduce a novel dataset and evaluation protocol tailored for this new task of learning object-level concepts.
Learning Multiple Concepts from Single Image and Editing
teddy bear and skateboard example
Our method learns multiple new concepts and assures disentangled and precise prompt-concept correlation (click to view per-prompt attention maps).
We can then modify each concept by replacing the prompts/words to generate novel images (click words below to try editing).

Visuslise
attention-mask
of
"a photo of brown * (teddybear-attention)
on a rolling @ (skateboard-attention) at times square".

Edit
"brown * (panda / cat)
on a rolling @ (surfboard / blanket)
at times square."
banana and basket example

Visuslise
attention-mask
of
"a photo of brown * (basket-attention)
with yellow @ (banana-attention)".

Edit
"brown * (stainless-pot / pottery)
with yellow-@ (yellow-pineapple / green-grapes)
at times square."
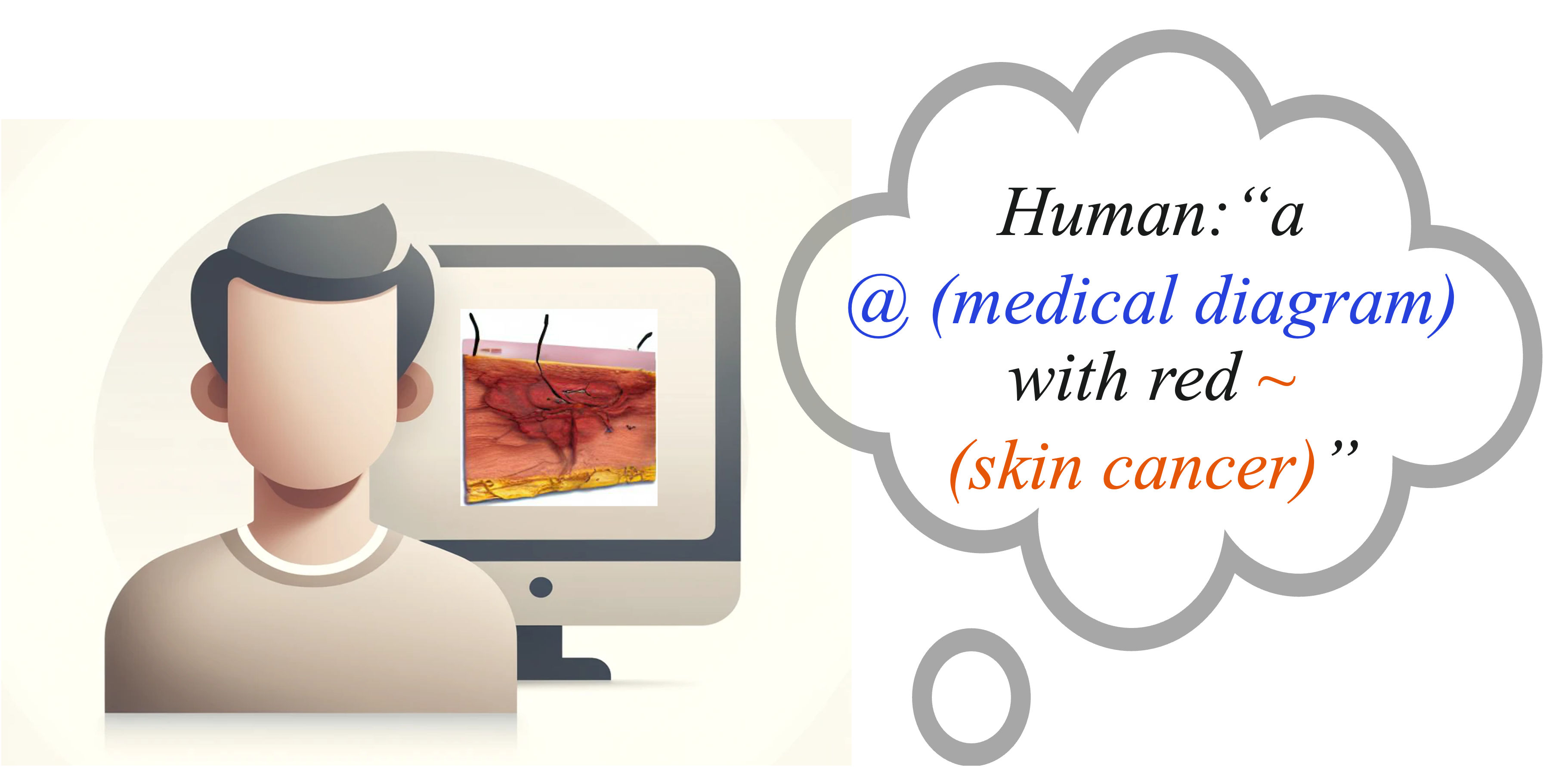
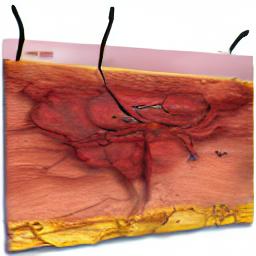
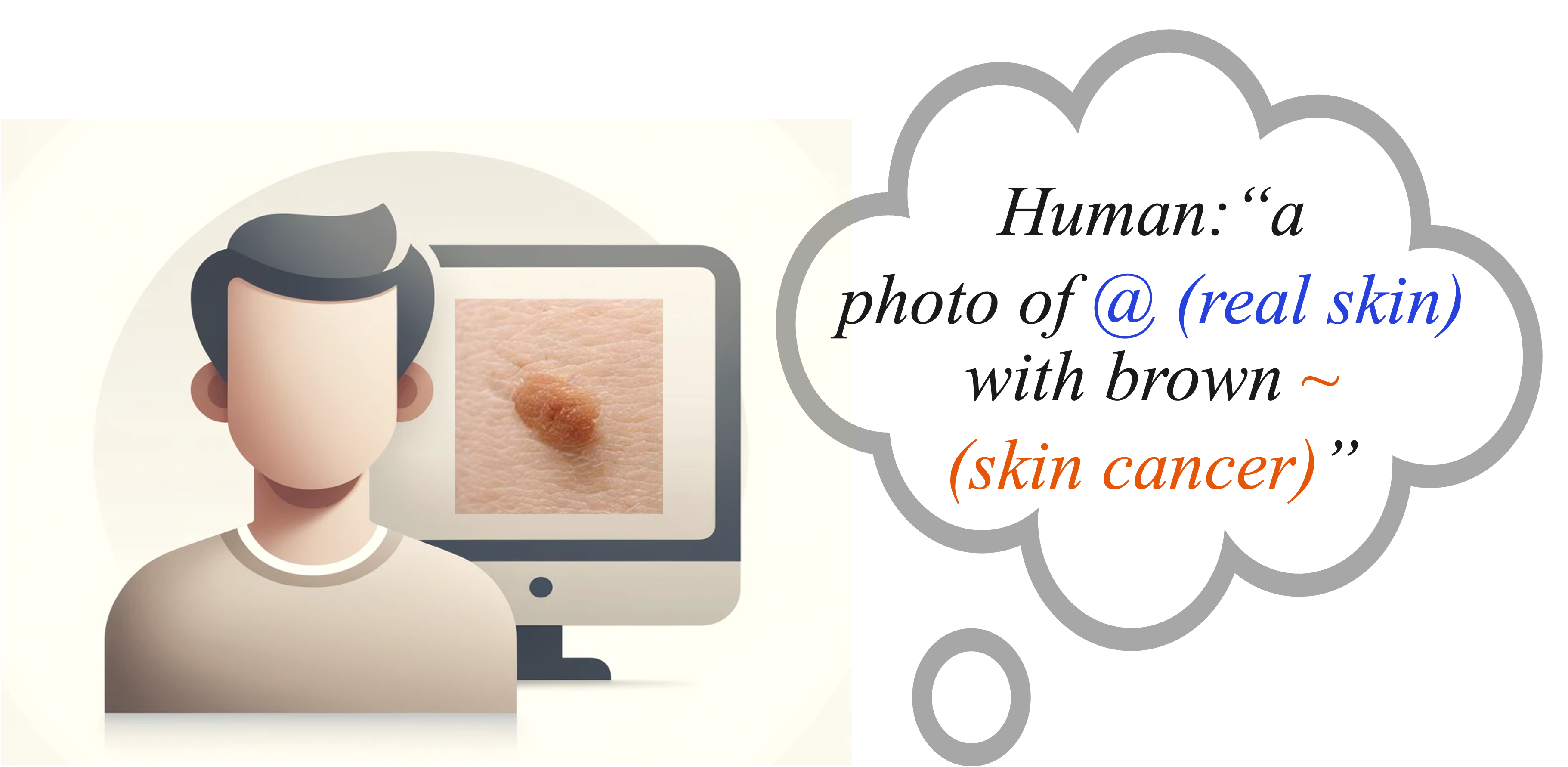
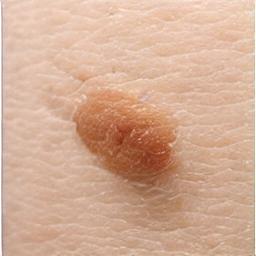
Discovering OOD Concepts from Medical Image and Disentangling
Our method opens an avenue for discovering/introducing new concepts the model have not seen before, from abundantly available natural language annotations such as paired textbook figures and captions.
cardiac MRI example
We learn out-of-distribution concepts using biomedical figures and their simplified captions.
We can then generate or remove each disentangled prompt to verify the learning of unfamiliar concepts.

Visuslise
attention-mask
of
"a photo of
! (cMRI-attention) with
round * (cavity-attention)
and thin @ (scar-attention) on the side circled by
yellow-lines-attention".

Generate
disentangled
round-*,
thin-@,
yellow-lines,
!,
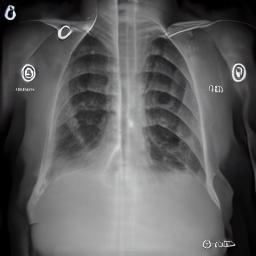
chest X-ray example
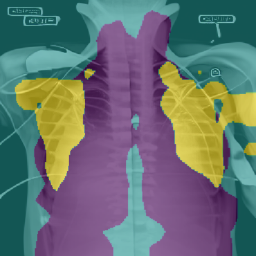
Visuslise
attention-mask
of
"a photo of
white ! (chest-X-ray-attention) and
black @ (lung-attention)
which have smoky * (consolidation-attention)".

Generate
disentangled
white-!,
black-@,
smoky-*,
or
remove white-!,
remove black-@,
remove smoky-*,
Hypothesis Generation of Disease Progression
Our method can also help experts/non-experts learn unfamiliar concepts from picture(s) and explore their impacts.
Method Overview
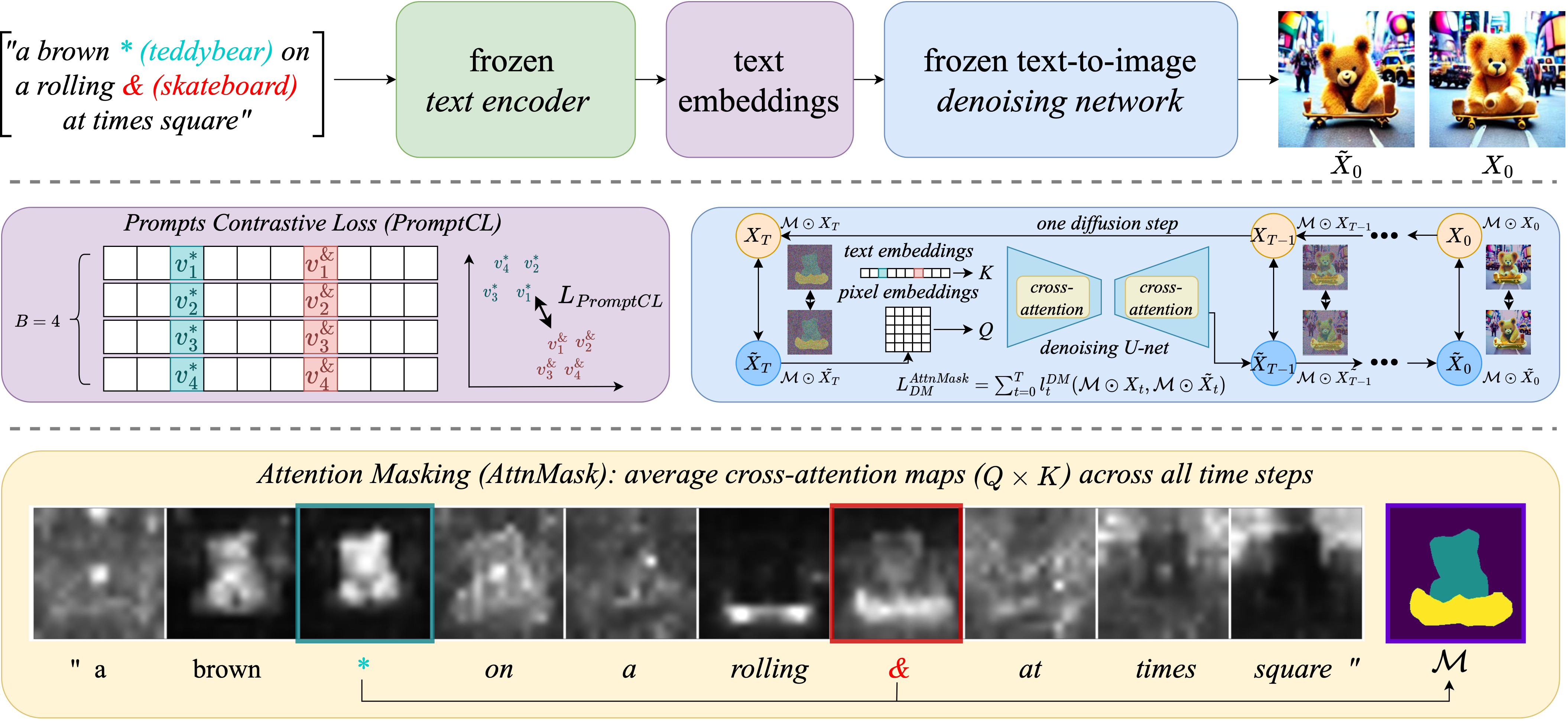
Prior methods failed due to inaccurate word-concept correlation. We fixed this by contrasting different concepts and aligning cross-attention with semantically meaningful regions of known words. Details are as follows: MCPL takes a sentence (top-left) and a sample image (top-right) as input, feeding them into a pre-trained text-guided diffusion model comprising a text encoder \(c_\phi\) and a denoising network \(\epsilon_\theta\). The string's multiple prompts are encoded into a sequence of embeddings which guide the network to generate images \(\tilde{X}_0\) close to the target one \(X_0\). MCPL focuses on learning multiple learnable prompts (coloured texts), updating only the embeddings \(\{v^*\}\) and \(\{v^\&\}\) of the learnable prompts while keeping \(c_\phi\) and \(\epsilon_\theta\) frozen. We introduce Prompts Contrastive Loss (PromptCL) to help separate multiple concepts within learnable embeddings. We also apply Attention Masking (AttnMask), using masks based on the average cross-attention of prompts, to refine prompt learning on images. Optionally we associate each learnable prompt with an adjective (e.g., "brown" and "rolling") to improve control over each learned concept, referred to as Bind adj.
Introducing MCPL-one and MCPL-diverse Training Strategies

Learning and Composing “ball” and “box”. We learned the concepts of “ball” and “box” using different methods (top row) and composed them into unified scenes (bottom row). We compare three learning methods: Textural Inversion (Gal et al., 2022), which learns each concept separately from isolated images (left); MCPL-one, which jointly learns both concepts from un- cropped examples using a single prompt string (middle); and MCPL-diverse, which advances this by learning both concepts with per-image specific relationships (right).
Ablation Studies
Comparing MCPL-diverse versus MCPL-one

Visual comparison of MCPL-diverse versus MCPL-one in learning per-image different concept tasks (cat with different hat example). As MCPL-diverse are specially designed for such tasks, it outperforms MCPL-one, which fails to capture per image different hat styles.
Learning more than two concepts from a single image

A qualitative comparison between our method (MCPL-diverse) and mask-based approaches. Our MCPL-diverse, which neither uses mask inputs nor updates model parameters, showed decent results, outperforming most mask-based approaches and was closer to SoTA Break-A-Scene. Images modified from Break-A-Scene (Avrahami et al., 2023).
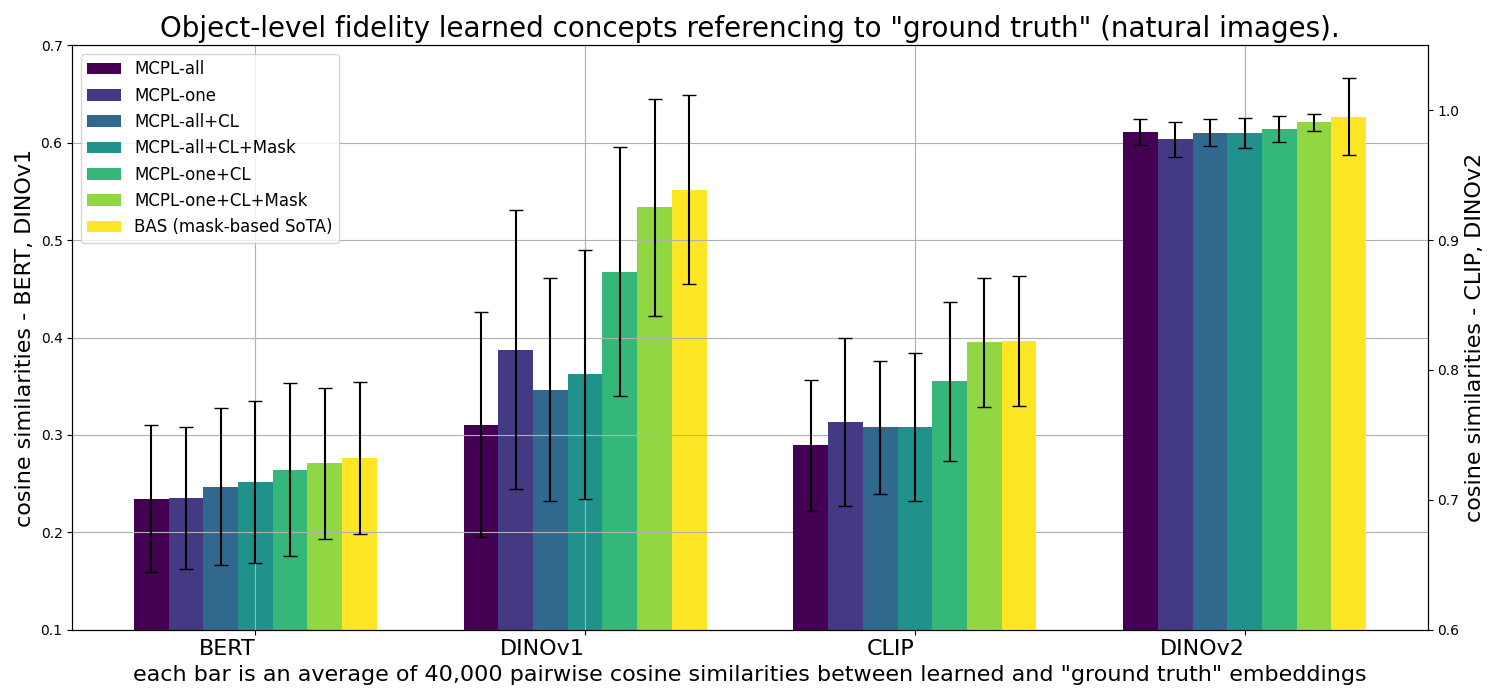
Quantitative Evaluations Dataset and Results
We collect both in-distribution natural images and out-of-distribution biomedical images over 16 object-level concepts, with all images containing multiple concepts and object-level masks.

Visualisation of the prepared ground truth examples (top) and the generated images with Break-A-Scene (bottom). Note that BAS requires segmentation masks as input and employs separate segmentation models to produce masked objects, thus serving as a performance upper-bound.
We compare three baseline methods: 1) Textural Inversion applied to each masked object serving as our best estimate for the unknown disentangled “ground truth” embedding. 2) Break-A-Scene (BAS), the state-of-the-art (SoTA) mask-based multi-concept learning method, serves as a performance upper bound, though it’s not directly comparable. 3) MCPL-all as our naive adaptation of the Textural Inversion method to achieve the multi-concepts learning goal.
The t-SNE projection of the learned embeddings
Our method can effectively distinguish all learned concepts compared to Textural Inversion (MCPL-all), the SoTA mask-based learning method, Break-A-Scene, and the masked ’ground truth.
Embedding similarity in learned object-level concepts compared to masked “ground truth”
We evaluate the embedding similarity of our multi-concept adaptation of Textural Inversion (MCPL-all) and the state-of-the-art (SoTA) mask-based learning method, Break-A-Scene (BAS) by Avrahami et al. (2023), against our regularised versions. The analysis is conducted in both pre-trained text (BERT) and image encoder spaces (CLIP, DINOv1, and DINOv2), with each bar representing an average of 40,000 pairwise cosine similarities.
BibTex
@inproceedings{
anonymous2024an,
title={An Image is Worth Multiple Words: Discovering Object Level Concepts using Multi-Concept Prompt Learning},
author={Anonymous},
booktitle={Forty-first International Conference on Machine Learning},
year={2024},
url={https://openreview.net/forum?id=F3x6uYILgL}
}